The differences in performance between different character sets and collations for MySQL 5.7 and MySQL 8.0 were studied by Percona in “Charset and Collation Settings Impact on MySQL Performance” blog post. Dimitri from MySQL compared these MySQL versions with MySQL 5.6 and MariaDB 10.3 in “MySQL Performance: more in depth with latin1 and utf8mb4 in 8.0 GA”. In the last comparison MariaDB showed smaller performance than MySQL in several benchmarks, so the issue MDEV-16413 “test performance of distinct range queries” was created and, later, fixed.
MDEV-16413 is about performance benchmarks, but the real development issues are MDEV-17474 and MDEV-17502. All the issues were closed years ago and the recent MariaDB 10.6 comes with many performance improvements, so we decided to reevaluate the performance benchmarks for the characters encodings and collations. In our tests we used MariaDB 10.6.2 (actually, a bit more recent 10.6 branch as of commit 891a927e804c5a3a582f6137c2f316ef7abb25ca). However, evaluating MariaDB only would be too boring, so we also took the latest MySQL 8.0.25 for the tests.
In our benchmarks we used a server with dual Intel Xeon E5-2630 v4 2.20GHz CPUs (40 hyperthreads), 128GB RAM DDR4 2133MT/s, and 1.2TB Intel SSDPE2MX012T7 (NVMe, P3520 Series). The machine is running CentOS 7.8 with the Linux kernel 5.4.105 installed for the standard repositories. We used devtoolset-8 to get GCC 8.3.1 for MariDB and MySQL servers compilation from sources. Both the servers were compiled with -DBUILD_CONFIG=mysql_release.
We used the same benchmarking scripts by Axel Schwenke. You can find the short instructions on how to run them in the MDEV-16413 comment. To run them you just need to make following steps:
- Download and build the MariaDB sysbench branch. The scripts use it as
sysbench-mariadb, so it might be handy to create a symbolic link to the built tool, e.g.ln -s /path/to/built/sysbench /usr/bin/sysbench-mariadb - Run the database server. We used the mariadb.cnf configuration file for MariaDB and mysql.cnf for MySQL
- Enter the collation directory inside the test suite, e.g. latin1
- Update
config.shinside the directory according to your installation. For our case we had to changeINST_DIR– installation directory,DATADIR– the database directory,SOCKET– mysql connection socket,CORES– the CPU number of your hardware. Don’t forget to setIS_MYSQL=1for MySQL tests. - Run the test, e.g. as
./run.sysbench 10. The number is just a suffix of the newly created directory with the test results. We used 10 for MariaDB and 11 for MySQL, so you can observe the results on the directories res10 and res11 correspondingly.
This is an OLTP read only test over 1 InnoDB table with 100000 rows, which executes queries like (this is SQL-with-LUA-mixed pseudocode):
range_start = rand(1, 100000)
SELECT DISTINCT c FROM sbtest
WHERE id BETWEEN range_start
AND range_start + oltp_range_size - 1 ORDER BY c
, where oltp_range_size is 10 or 100 for short or long tests correspondingly. The table is created as:
CREATE TABLE sbtest (
id INTEGER UNSIGNED NOT NULL,
k INTEGER UNSIGNED DEFAULT '0' NOT NULL,
c CHAR(120) COLLATE utf8mb4_general_ci DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
) /*! ENGINE = innodb MAX_ROWS = 100000 */
There are 2 specific points about the workload:
- The data set is very small, so it’s pure CPU-bound workload
ORDER BY cinvolves many string comparisons inutf8mb4_general_cicollation.
We’ll go deeper into what’s going on in the databases on this query a bit later, but now let’s have a look into performance of MariaDB and MySQL for this workload. MariaDB (in green) shows better results in all the tests:
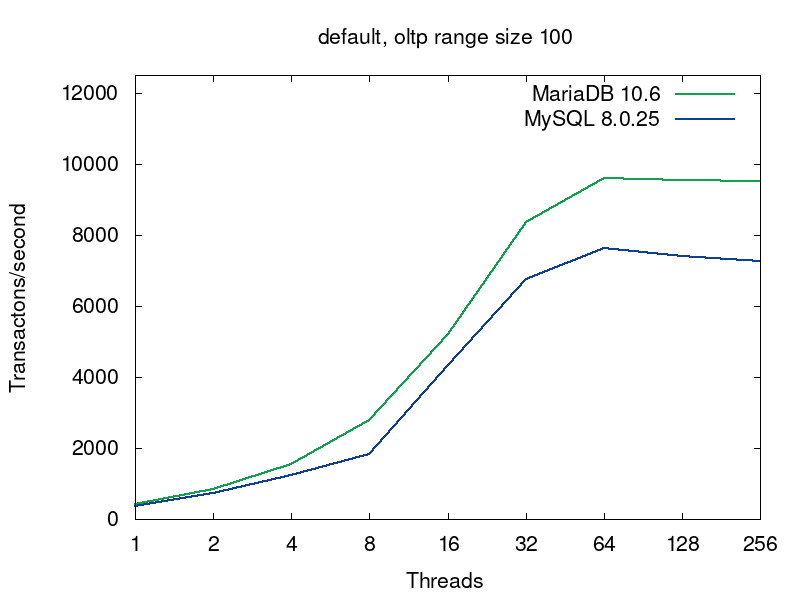
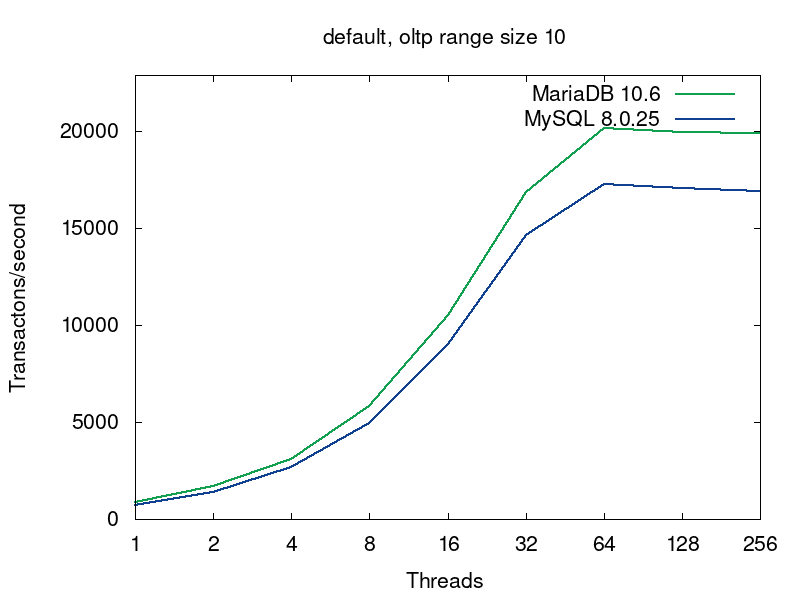
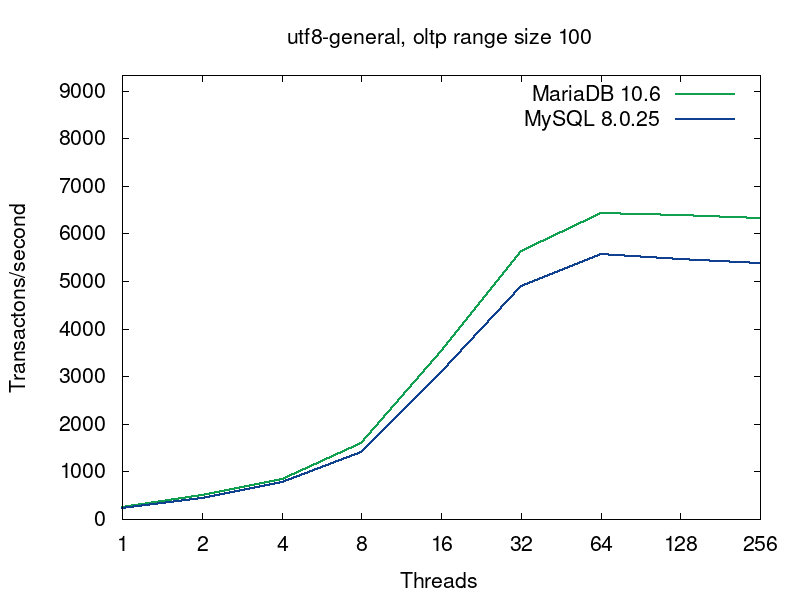
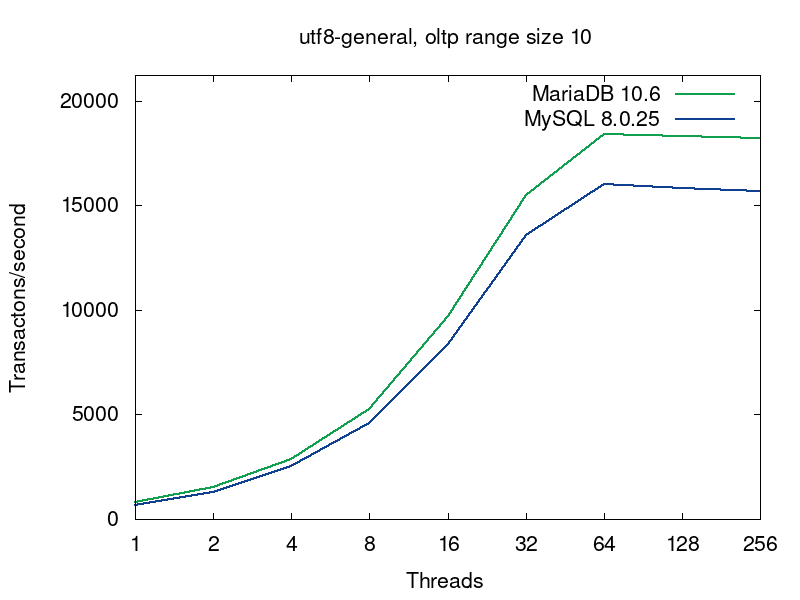
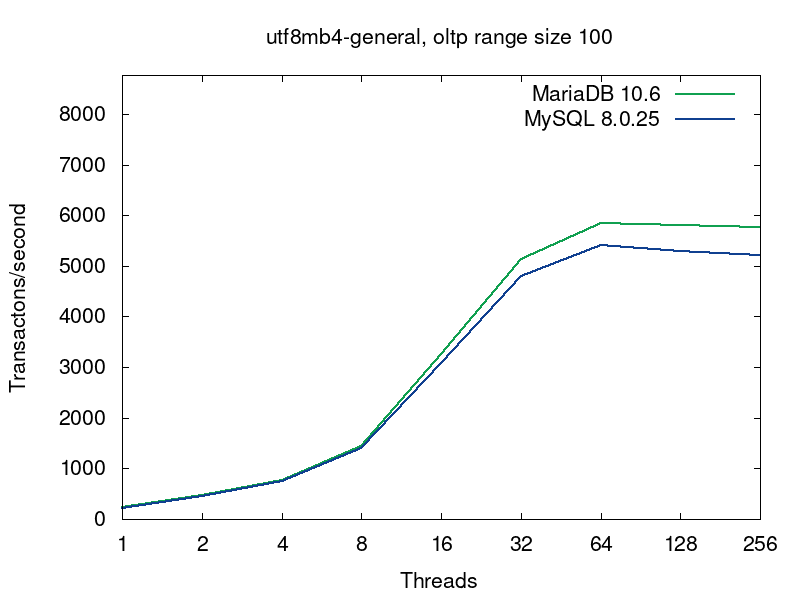
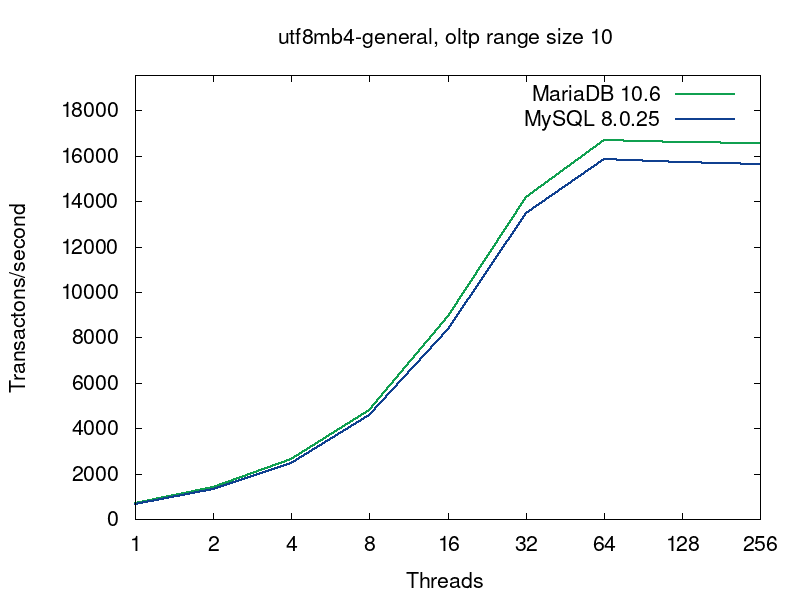
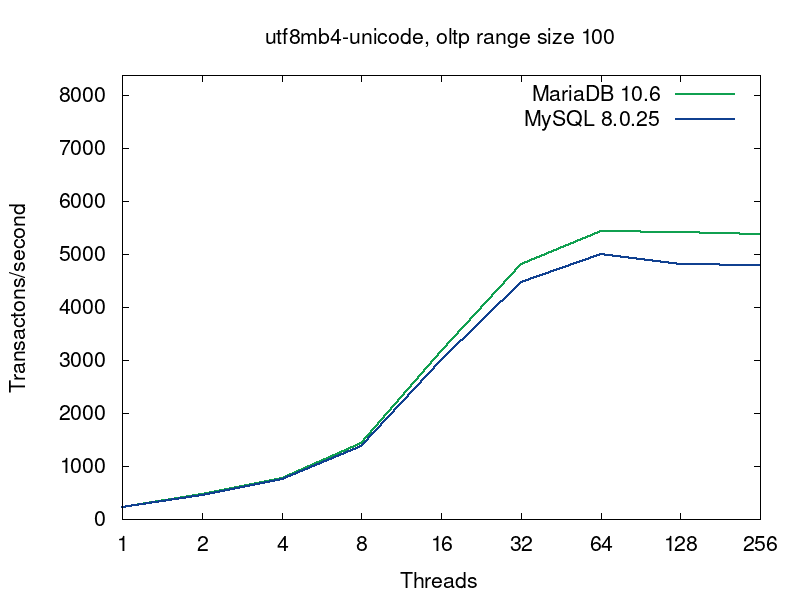
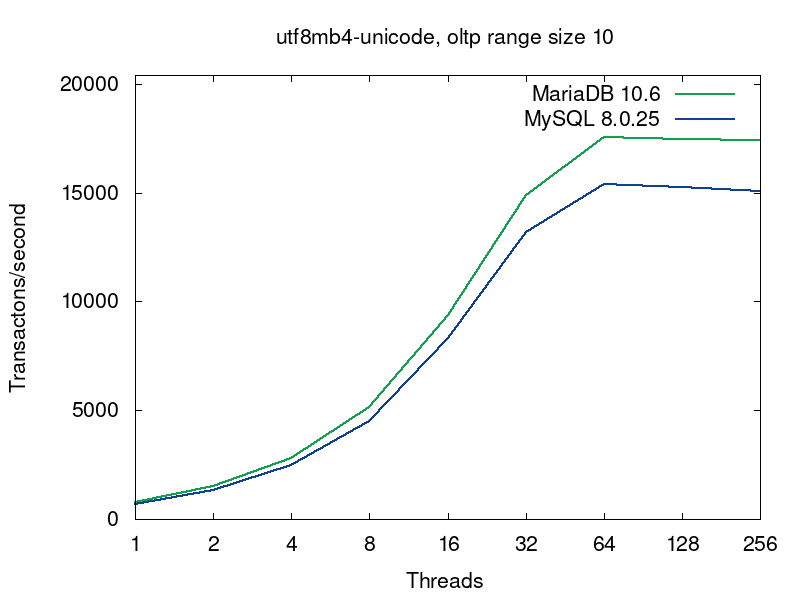
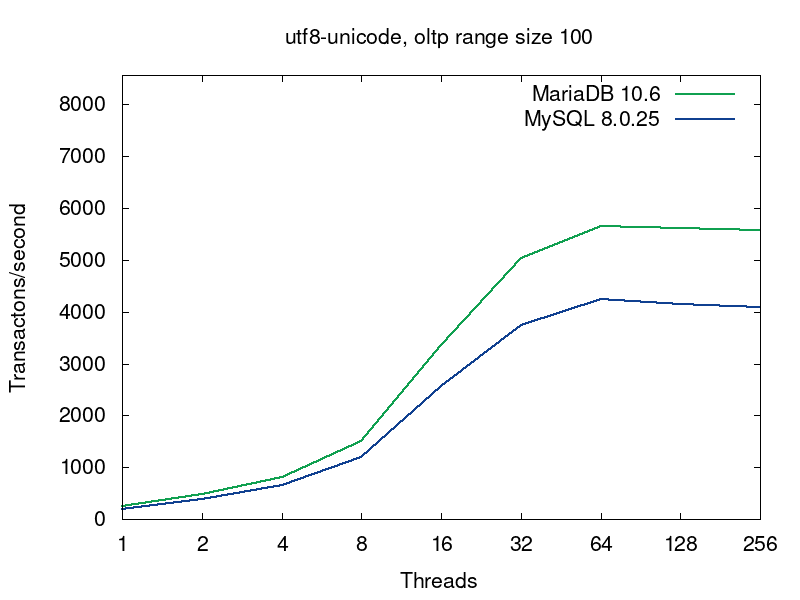
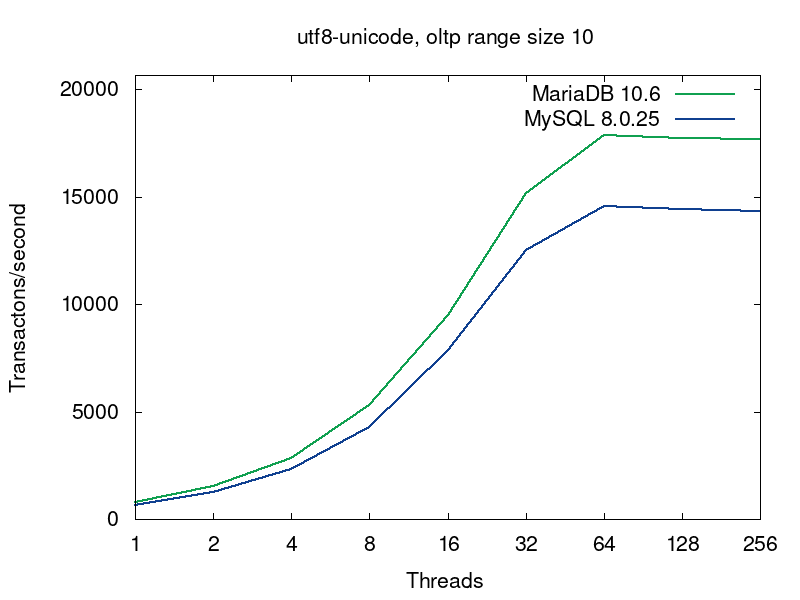
The first pairs of the graphs compare MySQL and MariaDB running with the default collations, i.e. the tables were created without any collation specification (see the script):
CREATE TABLE sbtest (
id INTEGER UNSIGNED NOT NULL,
k INTEGER UNSIGNED DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
) /*! ENGINE = innodb MAX_ROWS = 100000 */
The default collations are the fastest for both of the servers. For MariaDB latin1_swedish_ci is the default collation. The default collation for MySQL 8.0 is utf8mb4_unicode_520_ci. As we see from the first pair of graphs, if both the servers are serving tables with the default collations, then MariaDB provides better performance. The next 4 pairs of graphs compare 4 more collations for UTF8.
There are 2 interesting questions:
- Why character encodings and collation impact the performance?
- What’s the reason for the MariaDB better performance?
From MDEV-17474 and MDEV-17502 the main changes are:
- Replacing virtual calls with templates instantiation and inlined code
- Fast paths for ASCII
There are 3 commits introducing the performance improvements: a8efe7ab1f28e2219df5ae9aa88fa63c40ad1066, 475c6ec551fa8847f8993e7cb2d3ff1119f29f5a, 6eae037c4c76a5746f3954356a5a8b78da49dd1b.
As we discussed above the workload involves many string comparisons and the testing table uses different character sets and collations. Collation is the set of rules on how to compare strings for a particular character set (the MySQL doc provides a very clear example of collation). I.e. the strings comparison works as fast as efficiently the collations are implemented. There are a lot of different character sets and there are different collations for at least some of them, so a lot of virtual functions were used to initially implement collations. This is what MDEV-17474 is about: replace the virtual function calls with templates. The issue mentions ctype-uca.ic, which is directly included in the C files, e.g. ctype-ucs2.c, and uses many defined functions and tables. This is a C templating in steroids: each inclusion of strcoll.icgenerates not only typed specializations of the functions (in terms of C++), but actually completely different implementations. E.g. the specialization of strnncollsp() function (which is just a wrapper for strnncoll()), used to compare two strings according to the collation, calls scan_weight() (in the sake of brevity we skip some comments and assertions):
static int
MY_FUNCTION_NAME(strnncoll)(CHARSET_INFO *cs __attribute__((unused)),
const uchar *a, size_t a_length,
const uchar *b, size_t b_length,
my_bool b_is_prefix)
{
const uchar *a_end= a + a_length;
const uchar *b_end= b + b_length;
for ( ; ; )
{
int a_weight, b_weight, res;
uint a_wlen= MY_FUNCTION_NAME(scan_weight)(&a_weight, a, a_end);
uint b_wlen= MY_FUNCTION_NAME(scan_weight)(&b_weight, b, b_end);
if (!a_wlen)
return b_wlen ? -b_weight : 0;
if (!b_wlen)
return b_is_prefix ? 0 : a_weight;
if ((res= (a_weight - b_weight)))
return res;
a+= a_wlen;
b+= b_wlen;
}
return 0;
}
MY_FUNCTION_NAME() macro generates strnncoll() specializations for each collation and uses collation-specific specializations for scan_weight(). Let’s have a look onto the last function definition:
static inline uint
MY_FUNCTION_NAME(scan_weight)(int *weight, const uchar *str, const uchar *end)
{
if (str >= end)
{
*weight= WEIGHT_PAD_SPACE;
return 0;
}
#ifdef IS_MB1_CHAR
// ....
#endif
#ifdef IS_MB1_MBHEAD_UNUSED_GAP
// ....
#endif
#ifdef IS_MB2_CHAR
// ....
#endif
#ifdef IS_MB3_CHAR
// ....
#endif
#ifdef IS_MB4_CHAR
if (str + 4 > end) /* Incomplete four-byte character */
goto bad;
if (IS_MB4_CHAR(str[0], str[1], str[2], str[3]))
{
*weight= WEIGHT_MB4(str[0], str[1], str[2], str[3]);
return 4; /* A valid four-byte character */
}
#endif
bad:
*weight= WEIGHT_ILSEQ(str[0]); /* Bad byte */
return 1;
}
Only IS_MB4_CHAR is defined for the utf8mb4, so the function shrinks to only the last #ifdef block. The specialization is generated by definitions of the macros and inclusion of the .ic file:
static inline int my_weight_utf32_general_ci(uchar b0, uchar b1,
uchar b2, uchar b3)
{
my_wc_t wc= MY_UTF32_WC4(b0, b1, b2, b3);
if (wc <= 0xFFFF)
{
MY_UNICASE_CHARACTER *page= my_unicase_default_pages[wc >> 8];
return (int) (page ? page[wc & 0xFF].sort : wc);
}
return MY_CS_REPLACEMENT_CHARACTER;
}
#define WEIGHT_MB4(b0,b1,b2,b3) my_weight_utf32_general_ci(b0, b1, b2, b3)
#include "strcoll.ic
We need completely different methods implementations, not just the same code for different types. This is doable through specialization of whole C++ template classes. We can not compare the MariaDB code directly with MySQL, because we’re interested in the implementation of the different collation. But MySQL doesn’t use C++ templates extensively enough. For example, the collation string comparison function my_strnncoll_uca_900() still executes character sets checks in run time instead of using characters set specific specialization:
static int my_strnncoll_uca_900(const CHARSET_INFO *cs, const uchar *s,
size_t slen, const uchar *t, size_t tlen,
bool t_is_prefix) {
if (cs->cset->mb_wc == my_mb_wc_utf8mb4_thunk) {
switch (cs->levels_for_compare) {
case 1:
return my_strnncoll_uca, 1>(
cs, Mb_wc_utf8mb4(), s, slen, t, tlen, t_is_prefix);
case 2:
return my_strnncoll_uca, 2>(
cs, Mb_wc_utf8mb4(), s, slen, t, tlen, t_is_prefix);
default:
assert(false);
case 3:
return my_strnncoll_uca, 3>(
cs, Mb_wc_utf8mb4(), s, slen, t, tlen, t_is_prefix);
case 4:
return my_strnncoll_uca, 4>(
cs, Mb_wc_utf8mb4(), s, slen, t, tlen, t_is_prefix);
}
}
....
The conditional branch is executed only once for a strings comparison and the switch statement is essentially just an indirect function call (Spectre mitigation makes it slower though, you can find details on the compiler optimization in our SCALE 17x talk). More importantly is that the my_strnncoll_uca() calls generic UTF-8 characters processor my_mb_wc_utf8_prototype() through the Mb_wc_utf8mb4::operator() – this function is called on each input character! So MySQL executes more code on each character comparison, which leads to the slower range queries.
UPDATE. There were claims that the benchmark isn’t relevant because usually people just specify default characters set and do not care about collations. utf8mb4 characters set is the most used nowadays. Indeed, just recently we saw a table storing posts for a web blog, which was created as:
CREATE TABLE `posts` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`post` blob DEFAULT NULL,
`img` varchar(100) DEFAULT NULL,
`snippet` varchar(1000) DEFAULT NULL,
`date` date DEFAULT NULL,
`meta` varchar(1000) DEFAULT NULL,
`keywords` varchar(200) DEFAULT NULL,
`modified` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=42 DEFAULT CHARSET=utf8mb4;
In this case MySQL 8.0 uses the collation utf8mb4_unicode_520_ci and MariaDB uses utf8mb4_general_ci. So we asked Axel Schwenke for the additional benchmark for the collations. Hopefully, Axel could run the benchmark on the same hardware. Besides the benchmarks itself, he updated the scripts to use sysbench 1.0. The new scrips and results can be found in our GitHub repository. The benchmark results are described in DESC file, i.e. res05 directory contains the results for MariaDB with the default utf8mb4 collation and res24 for MySQL utf8mb4_unicode_520_ci. Let’s have a look on the graph.
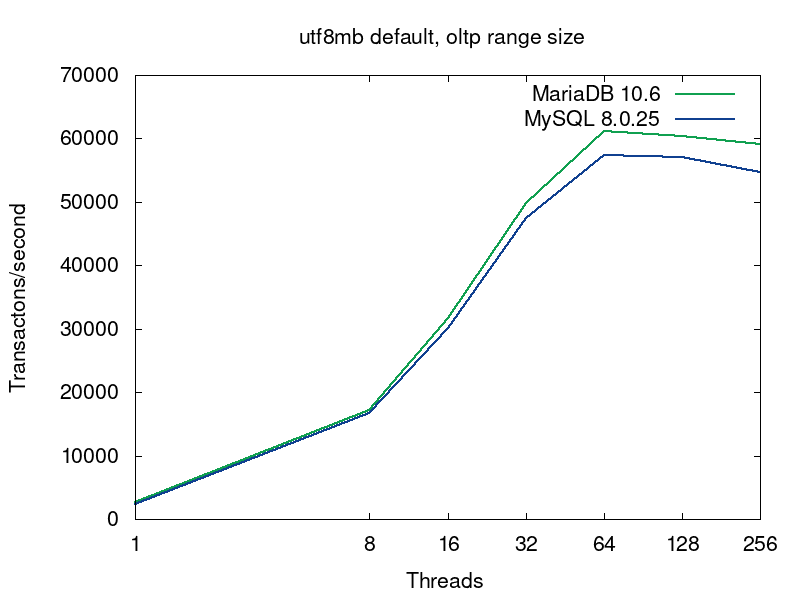
As we see, the results are still the same – MariaDB collations are still faster than in MySQL. You might notice that the absolute results are higher than in the previous benchmarks, so we asked Axel about this and here is the answer:
That is expected. The old collations benchmark was using
sysbench-mariadb which is basically a branch off sysbench-0.5. Now I
switched to sysbench-1.0 (1.0.20 to be exact). It is much faster and uses
prepared statements by default.
There results weren’t surprising after reviewing code of both the implementations in MariaDB and MYSQL.
We are hiring! Look for our opportunities
Need faster, scalable software?