During the global pandemic, the load and demand for remote communication has increased. Remote communication systems store information about tariffs, subscribers, various cost characteristics and take into account the traffic of subscribers or their groups, i.e. have a billing function. Any billing system is created on the basis of a specific database management system (DBMS) to store this information. In this situation of demand for remote communication, the client decided to expand his telecommunications business by launching a VoIP startup and implementing his billing system to support its needs following Lean Startup principles.
Many startups experience large financial pressure while developing the new product offering, largely due to absence of external financing and macroeconomic turbulence causing people to cut on investment risk. Startups in response would seek for a way to rely on operational profit to grow. But how to do it if you are really new and aren’t profitable yet?
Lean startup concept answers that question with a suggestion to be modest in terms of offering and the means you utilize in the early stage of your development as opposed to creating something complex and ready with long and intensive preparation. The cycle would go like that: the company develops the minimal viable product (MVP, the product only purpose of which is to demonstrate and test the main functionality) or only one additional feature in the product, then post release of MVP or that feature, feedback is received and measured to form a hypothesis or a design idea to be implemented in the next cycle.
The client we are going to discuss today did exactly that, having developed a MariaDB driven billing system for his service, utilizing very modest private resources (AKA startup owner’s own money and programming skills) in absence of external funding and then using first adopters’ feedback and fees to upgrade the code with expert help as soon as one got to the stage when one could afford it. Let’s discuss how it went…
MariaDB User Defined Functions
The billing system had to execute certain logic during processing data in the database. One example of such logic (but there are other examples as well) is cryptographic computations over the updated database rows. Following the Lean strategy requires doing one with a very small amount of as simple code as possible. Meantime, the workload for the billing system causes significant load. Thus, instead of developing a complex application logic sending many small queries to the database, our client decided to move some parts of the application logic to the database and minimize the number of database queries.
This way he came to the extension of the MariaDB functionality with the specific billing logic. As a matter of fact, MariaDB (as well as MySQL) provides the user-defined functions (UDF), the mechanism to extend the database with new functionality implemented in C++. There is also a lib_mysqludf_sys library containing a number of UDF functions that allows one to interact with the operating system – the execution environment in which the database server runs. With this library you can run almost any arbitrary program right from an SQL statement. Our client used the library to run the billing application logic scripts right from the database.
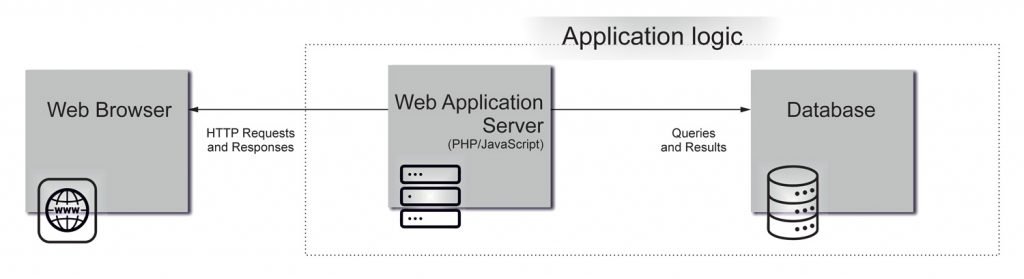
Opposing the more conventional way application logic would be executed (see the picture below), UDF is a way to extend MySQL/MariaDB with new functions that work like built-in MySQL/MariaDB functions such as COUNT() or CONCAT(). Since a UDF-extended database runs an application server, it looks and smells like an application server (yes, exactly, just like Nginx Unit or OpenResty!). Looks crazy? Maybe, but the communications between the application logic and the database becomes negligible. Moreover, there is Tarantool database, which provides you LuaJIT to write an application logic in Lua directly working with the database.
To prototype the billing system our client just wrote several lines of Python script which was called by lib_mysqludf_sys right from SQL statements. And that’s all – the core of the billing system was done!
The system indeed started working successfully, but according to forecasts of growth in the number of users and estimates of the volume of potential users, after some time the performance of the lib_mysqludf_sys functions might not be enough for him, that risked to provoke major slow down and thus cause a time lag in client’s billing process – a major pain potentially leading to orders bounce, customers dissatisfaction and flood of tickets to technical support. Client turned to us to speed up some of the lib_mysqludf_sys functions. In particular, it was necessary to speed up sys_eval()/sys_exec().
sys_eval() takes one command string argument and executes it, returning its output. The function uses popen().
sys_exec() takes one command string argument and executes it, w/o returning its output. It returns only an (integer) exit code. The function uses system().
system() and popen() executes commands by calling the shell (/bin/sh -c ...), so you can use any shell constructs – pipelines, environment variables, etc.sys_eval("cat file | grep line")
When clarifying the task, we found that for both the functions it was necessary to run separate simple commands and scripts. There was no need for pipelines, environment variables, etc. We decided to introduce the new fast implementations of these functions – sys_eval_fast()and sys_exec_fast().
The original sys_eval() and sys_exec() accept a command with all arguments as a string, so the shell has to parse the string.sys_eval("lsb_release -i -s")
This parsing causes some overhead and can be eliminated because the new functions can immediately accept the name of the executable file and each of the parameters, if any, at the input:sys_eval_fast("lsb_release", "-i", "-s")
Since we didn’t need to run the commands from shell, fork() and exec() system calls were suitable for our needs. To execute a command, we call exec() just after fork(), so fork() can be replaced with a lighter call vfork(), which avoids copying the page tables of the parent process. vfork() followed by exec() is the common idiom to execute a new process in Linux, but there is an less known alternative – posix_spawn(), which is a glibc wrapper function over clone()+exec(). Both the vfork() and posix_spawn() in Linux use the low-level system call clone().
In the simple case, using a posix_spawn() is not more complicated than a system().
if (posix_spawnp(&pid, "executable_file", NULL, NULL, argv, NULL) != 0) {
...
}
waitpid(pid, &status, 0);
If it is necessary to use unnamed pipes, some code is required to interact with the running program.
if (pipe(cout_pipe)) {
...
}
if ((r = posix_spawnattr_init(&attr)) ||
(r = posix_spawnattr_setflags(&attr, POSIX_SPAWN_USEVFORK))) {
...
}
if ((r = posix_spawn_file_actions_init(&actions))) {
...
}
posix_spawn_file_actions_addclose(&actions, cout_pipe[0]);
posix_spawn_file_actions_adddup2(&actions, cout_pipe[1], 1);
posix_spawn_file_actions_addclose(&actions, cout_pipe[1]);
if ((r = posix_spawnp(&pid, "executable_file", &actions, &attr, argv, nullptr))) {
...
}
close(cout_pipe[1]);
...
close(cout_pipe[0]);
Let’s use strace -c ... to see what happens when we execute ls program with system():
...
680688 clone(child_stack=0x7f48cd2e2ff0, flags=CLONE_VM|CLONE_VFORK|SIGCHLD
680689 execve("/bin/sh", ["sh", "-c", "ls"], 0x7fffa7b8bf18 /* 25 vars */
...
680689 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD
680690 execve("/usr/bin/ls", ["ls"], 0x55fc253cfb48 /* 26 vars */
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
70,57 21,012756 2626 8000 wait4
28,58 8,510547 1063 8004 clone
0,74 0,220466 27 8001 execve
0,10 0,030659 1 16002 8001 arch_prctl
------ ----------- ----------- --------- --------- ----------------
100.00 29,774428 40007 8001 total
As you can see, to execute ls via system() Linux creates two processes – one for the shell and the second for ls itself. The situation is different for posix_spawn():
...
682342 clone(child_stack=0x7f284297cff0, flags=CLONE_VM|CLONE_VFORK|SIGCHLD
...
682343 execve("/usr/bin/ls", ["ls"], NULL
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
59,14 10,033202 2500 4013 13 wait4
39,93 6,773719 1691 4004 clone
0,84 0,142870 8 16001 12000 execve
0,09 0,015721 1 8002 4001 arch_prctl
------ ----------- ----------- --------- --------- ----------------
100.00 16,965512 32020 16014 total
Here, by getting rid of the shell call, we reduce the number of created processes in half.
Let’s compare the execution time of system() and posix_spawn(). Both the programs make 1000 calls in 4 threads on 4 cores (Intel(R) Core(TM) i5-7300HQ CPU @ 2.50GHz):
| time | posix_spawnp | system |
|---|---|---|
| real | 0m0,972s | 0m1,817s |
| user | 0m2,905s | 0m5,455s |
| sys | 0m0,726s | 0m1,167s |
The benchmarks for popen() and posix_spawn() give us following numbers:
| time | posix_spawnp w/ pipe | popen |
|---|---|---|
| real | 0m1,155s | 0m1,987s |
| user | 0m3,023s | 0m5,596s |
| sys | 0m0,902s | 0m1,398s |
Test application code you can find here.
Providing 1.72-2 times more rapid response over sys_exec() and sys_eval() functions, as we see from the test results above, posix_spawn()was chosen for the implementation of sys_exec_fast() and sys_eval_fast().
The web application backend
One of the required UDF functions issues signatures for authentication in the video conferencing service and it was necessary to develop a small web application for this functionality. Our client is running an early stage bootstrap startup, so it’s crucial for him to be able to support the application himself and without significant programming effort. In short, the solution must not only handle a significant load, but also be as simple as possible.
Together with the client, we considered the following platforms to implement this application.
C/C++
Our team is mainly engaged in high performance & high availability systems and thus happens to be very fond of C/C++. If performance does matter for you, then with C and C++ you can develop the fastest code (yes, in some cases C/C++ gives you more performance optimization tools than Rust).
C++ is used in web development, e.g. Programming languages used in most popular websites show that 6 of 12 largest websites do use C++. Quora, the quite large and heavily loaded web resource, uses C++ (see What programming language is used on Quora?) as well.
With Nginx Unit you can develop C/C++ web applications (see the test C example). You may write C++ addons for Node.Js or use WebAssembly to get very fast Node.js applications. There are several web frameworks in C++, e.g. CppMicroServices, Wt, TreeFrog, CppCMS.
However, C++ is usually used for microservices, where you do some very specific and performance crucial logic. Microservices are usually accessed by web clients through a reverse proxy, so old and good HTTP/1 is enough for them. And there is plenty of modern development in the area: Boost.Beast, libhttpserver, Pistache, uWebSockets. The common property for the projects is that they can be used as a simple standalone HTTP server, just like the popular Gin in the Golang world. The servers are supposed to be used in a protected environment with no strict security or performance requirements. They implement very basic HTTP parsing without strict input validation and they do not care about high performance string processing (you can find details about development of fast and secure HTTP parsers in our SCALE 17x talk).
However, if you compare C++ with other languages, more popular in web development, e.g. Java or Python, you may find that C++ has poor libraries and doesn’t do favors for generic rapid web development. Besides, small standard library, C and C++, as well as Java, Rust and Go, are statically typed languages. Typically, dynamically typed languages like Python, PHP, JavaScript, Raku or Lua are more productive in terms of lines of code for the same functionality. Just check the programming languages benchmark game for gz column (the size of the program source code), e.g. Python vs Go – there are exceptions, but in most cases Python programs are much shorter than Go.
Once you have a big enough web resource that you have to care about performance, it makes little sense to develop everything in C/C++. Instead, you split your logic into many pieces (microservices) and develop some of them in a low-level and very fast language, e.g. C++. Typically, C/C++ is used for very fast microservices, which crunch some massive data. For this purpose, we have used the MariaDB UDF (also written in C++), but we needed some easy one to support web UI, so we sought out an option that wouldn’t require much speed but was easier.
Dynamically typed languages
The most performance critical part of our billing system is in C++ (MariaDB UDF), so now we need to choose a fast in run time and development time language (and an appropriate web platform) for the web application backend. In the previous section we ended up with forming the requirement that this should be a dynamically typed language, so Java and Go became out of scope.
In this section, we’ll discuss several benchmarks. Benchmarking is hard. Benchmarking of web application frameworks is even harder, because there are at least two things to benchmark. For example, you might wonder if Java is faster than JavaScript in one benchmark, then why a JavaScript application running on Node.js is faster than a Java application running in Tomcat in another benchmark? The thing is that to make a benchmark fair one needs to write the same code in all the tested languages/frameworks. Surely nobody will rewrite the whole real life web application in several frameworks, so the benchmark code is always small. The smaller the application code is, the bigger the performance impact the underlying platform ( in these cases – Node.js and Tomcat) causes. Tomcat is written in Java, while Node.js is in C++, so for the short benchmark code in Node.js wins.
PHP
One of the most popular web development languages is PHP. PHP became the backbone of the web we know, but originally it used I/O blocking, which means that when you make a request to get information from the database, the request is blocked until the data is received. Facebook developed HHVM (HipHop Virtual Machine) to make tons of existing PHP code run faster. However, with PHP version 7 its performance difference became negligible and some of the projects dropped support of HHVM (e.g. check the Symfony framework blog). HHVM adds powerful asynchronous and multi-threaded aspects, and PHP7 will be much more powerful with a version update, but PHP is still slower than Node.js.
Node.js
Node.js is built on V8, an open-source JavaScript engine, developed by The Chromium Project for Google Chrome and Chromium web browsers. Node.js uses multiple threads in its work. Separate threads are used for garbage collection, profiling, and compilation, several working threads for parallelizing work within one request, but the multiplexing thread is one. Nowadays there may be dozens of cores on one host. And if you want to scale to serve more concurrent connections, then you have to run multiple servers with load balancing or use the Cluster module. As a consequence of the used request processing model, I/O calls are non-blocking, but based on callbacks. It’s worth mentioning that the CPU cores load distribution proposed by the Cluster module is 2 steps behind the current Nginx model employing such socket options as SO_REUSEPORT and SO_INCOMING_CPU. These socket options allow you to process way more requests per second that the single-listener model. You can read more details on the topic in the CloudFlare post Perfect locality and three epic SystemTap scripts. One more usability issue of Node.js in comparison with Nginx is that you need additional scripting to server static files, not a big deal though.
Although in terms of performance it would be one of the best choices, JavaScript isn’t the easiest language to deal with and is known for the callback hell, so we decided not to go with it as our client needed something very simple and easy to manage.
Python
So we turned to Python as one of the languages with the smoothest learning curve. For Python interaction with the server, the WSGI protocol is used, which does not involve multiplexing and requests are executed one by one in the thread, blocking on input/output. For python, there is a more advanced uWSIG protocol using multiplexing. Not only that, but there is also PyPy, the JIT compiler for Python, which can run Python programs blazingly fast. So do we have the winner? Not yet. Let’s consider one more platform.
OpenResty
One more, which we needed to consider is Lua, LuaJIT running as part of OpenResty to be precise. We deal with web application firewalls (WAF) a lot so we obviously know OpenResty as a foundation for CloudFlare WAF and a very popular platform to build WAFs in general: many content delivery networks (CDNs) build their in-house WAF and application layer DDoS mitigation systems on top of OpenResty. Our team also participated in the development of WAF using the one.
OpenResty aggregates all the best from the Nginx world: the efficient request serving model and the speed of LiaJIT provided by the Nginx Lua module. There is a pool of threads that handle incoming requests from clients using multiplexing. Moreover, Nginx allows you to choose the most efficient multiplexing method for the platform. I/O calls are non-blocking, and this non-blocking is transparent, i.e. not based on callbacks (transparent coroutines look like blocking functions, but they don’t complicate the code). The Lua language is very simple and minimalistic, meaning less training time.
OpenResty is faster than Node.js and PHP. It’s comparable in speed with Go. How does it compare to PyPy? Sometimes it is slower than PyPy, in other tests, it might be faster or slower. However, recall our statement about benchmarking the web frameworks (well, application servers in this case) – this is an underlying HTTP server besides the programming language. OpenResty is just Nginx with the LuaJIT module and your Lua code runs directly in the Nginx process, right after an HTTP request processing. This is very different for Python – you need the uWSGI server, typically running behind the Nginx or other HTTP reverse proxy. The extra communications between the servers, messages serialization and deserialization, process and memory management, and other overhead just make the client -> Nginx -> uWSGI/PyPy chain much slower than simple client -> OpenResty processing.
All in all, the winner for our project was OpenResty.
The web application frontend
After a while, the client turned to us with a desire to expand the web part of the billing system following his initiative to develop a dealership/partnership distribution network for his startup. Our client, in addition to his ordinary clients, had to introduce dealers/partners, who would be granted master level access and who would be engaged in the process of startup services resale. He wanted to provide such dealers/partners with web access to a certain subset of client data so that they could review types of new clients’ information defined by business needs and view the data associated with their regular clients (such as their payments, for instance).
Since the application has already used several tables, it was decided to use one of the frameworks.
Since at the previous stage we proposed OpenResty for web development, it proved itself well and the client himself began to make improvements and extensions of his system as needed, it was decided to continue developing the web component using OpenResty and employ the Lapis framework [https://leafo.net/lapis/]. This framework contains all the main features, such as routing, handling HTTP verbs, error handling, HTML sanitization, input validation and verification, a powerful template language etlua, database access with escaping of replaced parameters, which makes SQL injections impossible, CSRF protection out of the box.
Also, plugins like DataTables and Tabledit were quite useful in the project.
Both plugins use an AJAX approach, in which the data of a web page is refreshed without completely reloading it, and web applications become faster and more convenient.
As a result of the work done, the client was able to grow his distribution network with dealers and partners supporting his sales while himself freeing up some time to take care of different business processes.
This article is contributed by Artyom Belov and Olga Grevtseva
We are hiring! Look for our opportunities
Need faster, scalable software?