Video on demand (VOD) is very special type of content: it weights a lot and it’s delivery is demanding to throughput and latency. A server node of a modern content delivery network (CDN) can easily service tens or hundreds of terabytes of video content.
If you’re Netflix or have budgets comparable with Netflix, then you can pack your CDN nodes with state-of-the-art NVMe SSDs. Otherwise you have to solve very non trivial question: which amount of RAM, NVMe SSD, SATA SSD, and/or HDD storage and in which proportion will deliver the best performance with lower cost. This question requires good analytics of the work set (the size, how quickly it’s changing, hits distribution and several other statistic measurements) and some mathematics modeling. (If you also need to answer the question, you can ask us for the answer.)
If you have some RAM and a lot of high capacity disks, then you typically use RAM to cache content from the disk. If you have ultra-fast NVMe SSDs or even Optane-like devices in one hand and slower, but high capacity, SATA SSDs or HDDs, then probably you split the content among the disks: more frequently requested video chunks are stored on the fastest drives and less frequently ones are on the slower high-capacity drives. This looks reasonable, but the recent paper The Storage Hierarchy is Not a Hierarchy: Optimizing Caching on Modern StorageDevices with Orthus claims that this isn’t the most efficient scheme.
Non-hierarchical caching for CDN
The paper presented on USENIX FAST’21 by Kan Wu et al. propose to service content from all available drives. If you have, say a fast NVMe SSD and a slow high-capacity HDD, it makes sense not only to use the NVMe drive as the cache for the HDD, but also deliver the same data chunks from both the drives to increase the total capacity.
The paper proposes an algorithm, which starts from usual caching approach, when all the data is cached on the fastest device according to a cache replacement algorithms. When, and if, cache hit stabilizes, the algorithm tries to send some data from the slow high-capacity device. The algorithm evaluates the performance according to a function, which could be resulting “throughput, latency, tail latency, or any combination”. If, for example throughput, increases with sending more data from the capacity device, then the algorithm tries to send even more data form the device, otherwise it sends more data from the faster device. In worst case the algorithm works not worse than the underlying cache replacement algorithm, but can improve it significantly during stable workloads. The block scheme of the algorithm is shown on the figure at the below from the original paper.
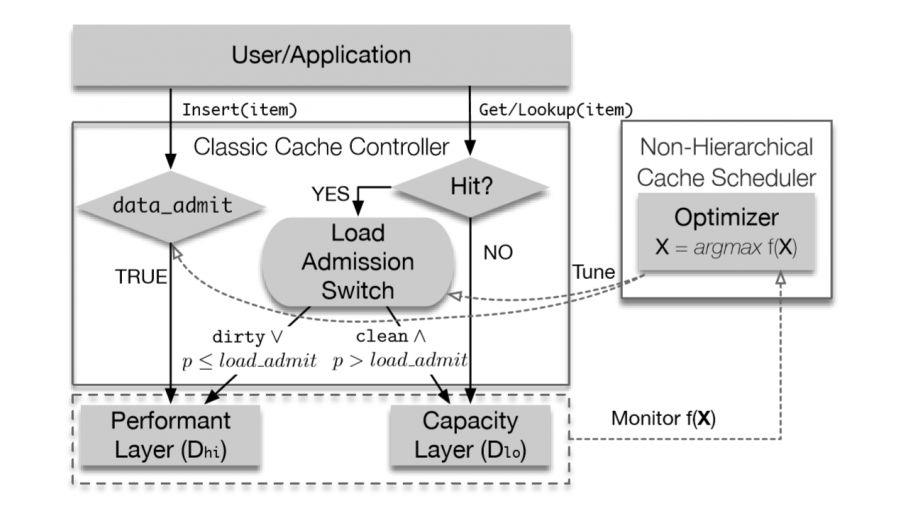
The algorithm looks very straightforward and quite reasonable. But there are couple of subtle questions though. First, we can run the optimization steps, which increase or decrease amount of data sent from the capacity device, only on stable cache hit, otherwise the metrics of the evaluation function can have as high deviations, as they become useless for the optimizations. The paper discusses the application of the algorithms to an operating system block layer caching system and a key-value LevelDB-based storage. For these conditions the authors used 0.1 second period to estimate current cache hit as stable. A CDN node, which has surely much lower number of cache hits per second, should have somewhat higher, and more importantly non-uniform cross different data chunks, stabilization period. The thing about video on demand (VOD) and live streaming cache is that cache hits must be accounted separately and for different periods of time. For example, 4 hours long Justice League was a top cache hitter for several days since the release. The video is large and all the chunks are requested frequently, so there is sense to move it to a faster data storage regardless write amplification. From the other hand, a live stream from a popular blogger has instant wave: only relatively small number of video chunks (current time plus or minus several seconds) are requested by large number of client for a relatively short period of time, while the stream is open. Most likely, you’ll move the recorded live stream to a faster storage only if it will be popular later, when the stream is closed. In both the cases stabilization time is very different, very different data sizes, and different decisions whether to move the data to a faster storage.
Second, the approach works for various disk types, but doesn’t work for RAM. If you have a file in both the memory cache and disk, then it does not make sense to try to send data from disk because it will go through RAM in any way, even if you use sendfile(). You can consider the proposed approach for data replicas in your HDD, SATA or NVMe SSDs, or Optane devices. But when we go to RAM, then only old good caching is still an option.
Lastly, while HDD are considered in the paper, there is assumption that “increasing the workload on a device does not decrease performance”, so the algorithm mostly targets flash devices. Moreover, besides the device medium, there are multiple queues inside a storage deice as well as on operating system layer. If we consider a CDN node, then we speak about the web cache of an HTTP server, i.e. there could be page cache involved or page eviction in OS virtual memory management layer. In other words, CDN caching is a high level mechanism which many I/O queues and the actual system performance will be lagging behind the algorithm decisions.
More about the caching algorithms
The proposed approach doesn’t limit you in which cache replacement algorithm you can use. If you use the most naive LRU, then you’re going to see improvement as if you use a more advanced algorithm. However, the ratio of the performance of the original cacheing to performance of non-hierarchical caching in both the cases shouldn’t be the same. So it’s worth mentioning that there are adaptive cache replacement algorithms, e.g. CART, a patent-free analog of famous ARC. We used CART for a fork on MySQL InnoDB storage engine back in 2011 and it did show much better performance than the standard LRU. There are also many research works in machine learning applications for cache replacement algorithms, e.g. Learning Cache Replacement with Cacheus from the same USENIX FAST’21 conference or the survey Applying Machine Learning Techniques for Caching inNext-Generation Edge Networks: A Comprehensive Survey. The algorithms demonstrate even better performance than the adaptive cache replacement algorithms. Probably the performance improvement for the non-hierarchical caching with the machine learning driven algorithms won’t reach the x2 factor as reported in the paper for naive LRU caches.
We are hiring! Look for our opportunities
Need faster, scalable software?